Preventing fraud payments in real time - case study
Please note: whilst being as detailed as possible, this article skips some business-specific issues.
One day in February 2016 I saw this message in my inbox:
I got a warning from Stripe about our chargebacks being too high. (…) I’m thinking that if the amount is more than $150 then the order needs confirmation. (…) We could also do something with failed payments and IP addresses with multiple credit cards and emails. (…) This is priority #1 right now. We should stop everything else at the moment.
My client runs a niche business in the telecom-related sector, with the payments operated by PayPal and Stripe. The inventory sold is purely virtual, with the delivery time ranging from minutes to days depending on the particular purchase, and my client acts as a middleman. Three types of cases concerning chargebacks were found after brief investigation:
Orders that are suspicious, as the end client tries different cards (how can we tell without knowing the full card details not to fall under the PCI DSS compliance will be discussed a little later), and some of the transactions are rejected, but succeed after few attempts. The client may try to change his identity between the attempts by clearing cookies and changing IP and email used, as my client’s service doesn’t require creating an account.
Orders that seem legit - paid on first attempt, no support tickets concerning the order can be found in the helpdesk so the client didn’t had any problems with the order, but due to the virtual nature of the inventory sold, the client issued a chargeback, hoping to end with both the item bought and the money that he was supposed to pay for it. Such cases can be battled manually by presenting evidence of client’s intent to Stripe after chargeback request.
Orders that seem legit, but due to delivery delays (it happens) the client decided to get a refund before the order was completed.
The first type of cases were where the most money was lost, so I’ve decided to focus on the most urgent matter first.
External services
As we were facing Stripe lockout if we don’t stop excessive chargeback number quickly, obviously the first step was to check the existing solutions. First prototype used one of the services available for ecommerce websites, but the outcomes were often vague and balancing on the edge between “accept - reject”. Moreover, with over 20,000 orders monthly, the fees for the fraud detection would cost a few thousands dollar a month, which is a considerable amount, and would continue to scale linearly as the business develops.
Naive approach
As the reaction to Stripe’s notice had to be instantenous, we’ve decided to go with the second quick prototype of the classifier consisting of manually crafted order checking rules, implemented in Python. The associations implying and order being a fraud were found manually, and the prototype was ready in under 3 days.
The transaction attempts were linked together by many transaction attributes, including but not limited to email address placed in the order form, IP address, Google Analytics identifier. This way a set of order along with related orders was fed to the classifier.
Some of the rules applied:
- If a client had a chargeback in the history, the order was rejected.
- If a client had more than 3 failed attempts with different credit cards, the order was rejected This can be checked by retrieving the cardholder names and last 4 card digits using Stripe API, without breaking PCI DSS compliance. Last 4 digits of the credit card number are enough to compare a few of the transaction to each other, but wouldn’t provide enough entropy when all orders would be considered - the “fingerprint” attribute would have to be used.
- If IP was associated with a known proxy or VPN server, the order was rejected. (We offer an API to check if given IP is blacklisted - mail us if you’re interested)
- If a client had more than 2 successful transactions on the same day, all further orders weren’t processed automatically, but required a manual review.
The first approach gave us some time to work on a more sophisticated solution, as the most obvious fraudulent transactions weren’t getting pass the payment step.
The final solution
Obviously the naive approach wasn’t the silver bullet for detecting high risk orders. The original implementation has been enhanced and extended in numerous ways.
Orders linking
The “linking” algorithm for finding related orders was considering only direct relations between transactions. Consider the following example:
| Order ID | IP | Fraud | |
|---|---|---|---|
| 1 | 9.9.9.9 | a@a.com | false |
| 2 | 5.5.5.5 | a@a.com | false |
| 3 | 5.5.5.5 | b@b.com | false |
The order number 1 can be linked with the order number 2 based on email, and the order number 2 can be linked to order number 3 besed on the IP. This gives us a strong foundation to believe, that a single person is responsible for placing all three orders.
Now if the chargeback will be issued for order ID 1, all linked transactions should also be put on hold, selected details of the transactions should be blacklisted, and all further orders for a client with any of attributes matching the ones blacklisted should be either rejected or marked as suspicious. This scheme is hard to implement in a classic relational model, thus graph database engine has been used - Neo4j.
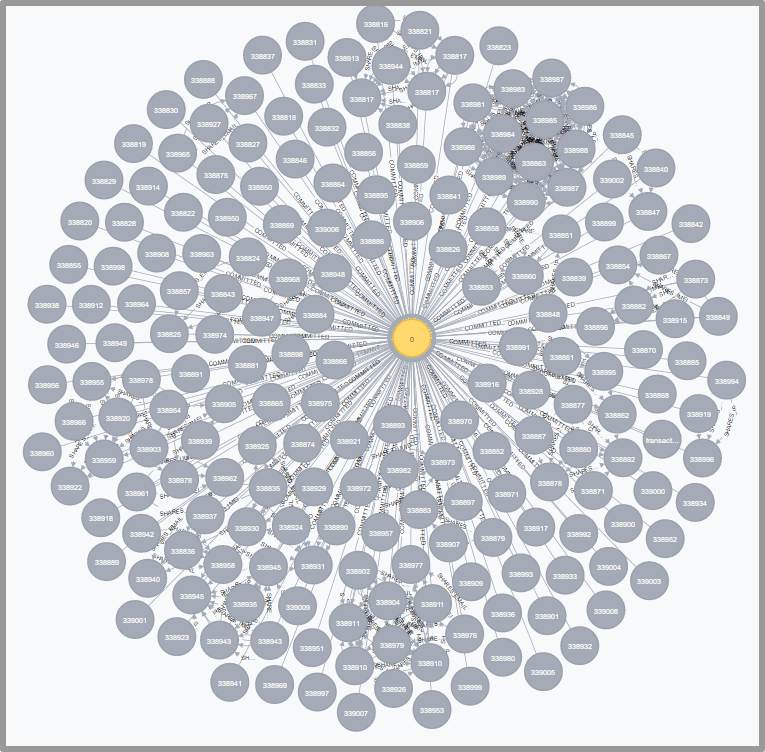
Graph showing connection between a subset of orders. The central node is a 'High Risk' node.
When a new chargeback comes, the order is marked as “High Risk” by connecting the corresponding node to the “High Risk” node. When a new transaction is checked, new vertex is created, and there’s an attempt to link the vertex representing an order to other ones, basing on shared attributes (including but not limited to the mentioned IP, email, Google Analytics ID).
The problem of checking if the checked order carrier a high risk of a chargeback basing just on the links between orders comes down to querying the engine, whether a path between the node representing the considered order and the “High Risk” node exists. At the same time, it is trivial to retrieve all connected orders. The outcome of this check is used in further processing steps, as described below.
Better classification rules
Only the human-observable associations were taken into account when creating the static classification rules in the initial prototype of the classifier. More information about associations between different attributes of the order could be helpful when taking the decision about the order classification.
The Apriori algorithm has been used to find relevant subsets of attributes that can be used for determining whether an order is legit or fraud. In this case, the attributes taken into consideration were extended from user-describing only to a larger space, including the item variations added to cart and behavioral information. It is also worth noting, that the confidence and support parameters for given attribute subsets had to be checked for both “fraud” and “legit” implications. If a implication of form
{attribute_1, attribute_2, attribute_3} -> Fraud
has a similar support as
{attribute_1, attribute_2, attribute_3} -> Legit
then there’s a great risk that using such implication in the classifier operation would result in a large number of false positives. The goal is to make the classifier transparent for legit users, and loosing revenue by too picky rules isn’t an option.
Some of the findings that came from search for association rules weren’t trivial:
- Hour of placing an order matters. It seems that fraudulent transaction appeared much more often on some hours.
- Some combinations of product variants bought had even 8x higher probability to end with a chargeback than others.
- Orders coming from a VPN had 10x higher probability to end with a chargeback.
- Some countries of origin raised the probability by 4x.
- Extraction of the mail service provider from a mail address put by the client has achieved a good results.
- User trying to change his identity by either changing IP or clearing cookies also increase the risk of a chargeback.
- The increasing number of failed orders rises the chargeback probability exponentially.
This is only the most interesting part of the findings, but how calculate the probability of an order being a fraud given so many information? We could try to assign weight to every rule by hand by doing some operations on support and confidence, but of course that wouldn’t be too effective. We’ve decided to go with Google’s Tensorflow library.
LinearClassifier, DNNClassifier, DNNLinearCombinedClassifier from the package tf.contrib.learn had been tested using
multiple association combinations found in previous step along with computed values and raw attributes. The search for the right
settings and parameter set was an exhaustive process, and by using different parameters for different classifiers it was possible
to achieve three disjoint models. Each one of the classifiers trained made independent errors, and each had a substantial level of
disagreement. This way, the combination of decisions
of three mentioned classifiers has been brought to a ternary decision - legit / manual review / fraud
using another instance of LinearClassifier.
The static rules present in the prototype haven’t been dropped - they have been extended to support incontestable pass / reject rules. For example, we’ve decided to drop all orders coming from VPN addresses no matter what would be the outcome from the classifiers.
Architecture
The final flow of the system is presented below.
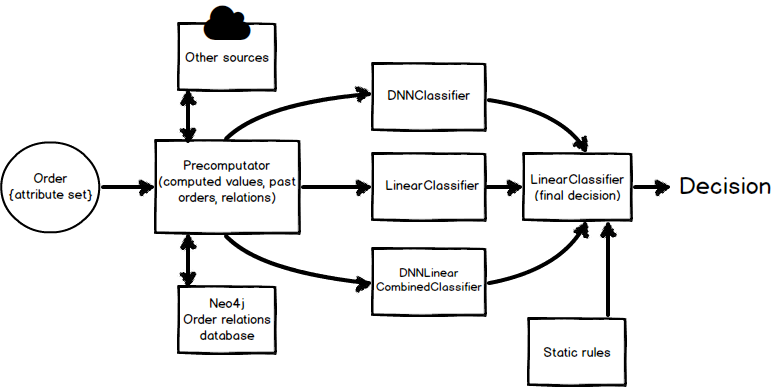
Flow chart showing the information flow of the classifier engine.
The system has been wrapped in a Docker container for simple load balancing and commissioning / decommissioning of the classifiers when the le-learning occurs, with simple API built in Flask. The system responds in the matter of seconds which is acceptable, and is wired to the payment system.
Summary
- The number of fraudulent orders has been reduced by 94%, resulting in tens of thousands dollars monthly cost reduction.
- Several accompanying components have been developed, eg. automatic evidence submission system for Stripe chargebacks, to minimize the effort needed to handle problematic cases.
- The algorithm has been used also to secure the PayPal transactions.
- The support team has more time to focus on handling tickets on Zendesk ;)
Drop us a note at pawel@devsti.me!